 By
By Enumerators are at the heart of what makes Ruby such a powerful, dynamic language. And lazy enumerators take this a step further by allowing you to efficiently work with extremely large collections.
Files - it turns out - are just large collections of lines or characters. So lazy enumerators make it possible to to some very interesting and powerful things with them.
What is an Enumerator anyway?
Every time you use a method like each, you create an enumerator. This is the reason that you can chain together methods like [1,2,3].map { ... }.reduce { ... } . You can see what I mean in the example below. Calling each returns an enumerator, which I can use to do other iterative operations.
# I swiped this code from Ruby's documentation http://ruby-doc.org/core-2.2.0/Enumerator.html
enumerator = %w(one two three).each
puts enumerator.class # => Enumerator
enumerator.each_with_object("foo") do |item, obj|
puts "#{obj}: #{item}"
end
# foo: one
# foo: two
# foo: three
Lazy enumerators are for large collections
Normal enumerators have problems with large collections. The reason is that each method you call wants to iterate over the whole collection. You can see this for yourself by running the following code:
# This code will "hang" and you'll have to ctrl-c to exit
(1..Float::INFINITY).reject { |i| i.odd? }.map { |i| i*i }.first(5)
The reject method runs forever, because it can never finish iterating over an infinite collection.
But with a small addition, the code runs perfectly. If I simply call the lazy method, Ruby does the smart thing and only does as many iterations as necessary for the computation. That's only 10 rows in this case, which is significantly smaller than infinity.
(1..Float::INFINITY).lazy.reject { |i| i.odd? }.map { |i| i*i }.first(5)
#=> [4, 16, 36, 64, 100]
Six thousand copies of Moby Dick
To test out these file tricks, we'll need a big file. One so large that any "failure to be lazy" will be obvious.
I downloaded Moby Dick from Project Gutenberg, and then made a text file containing 100 copies. That wasn't big enough, though. So I upped it to about 6,000. That means that right now I'm probably the only guy in the world who has a text file containing 6,000 copies of Moby Dick. It's kind of humbling. But I digress.
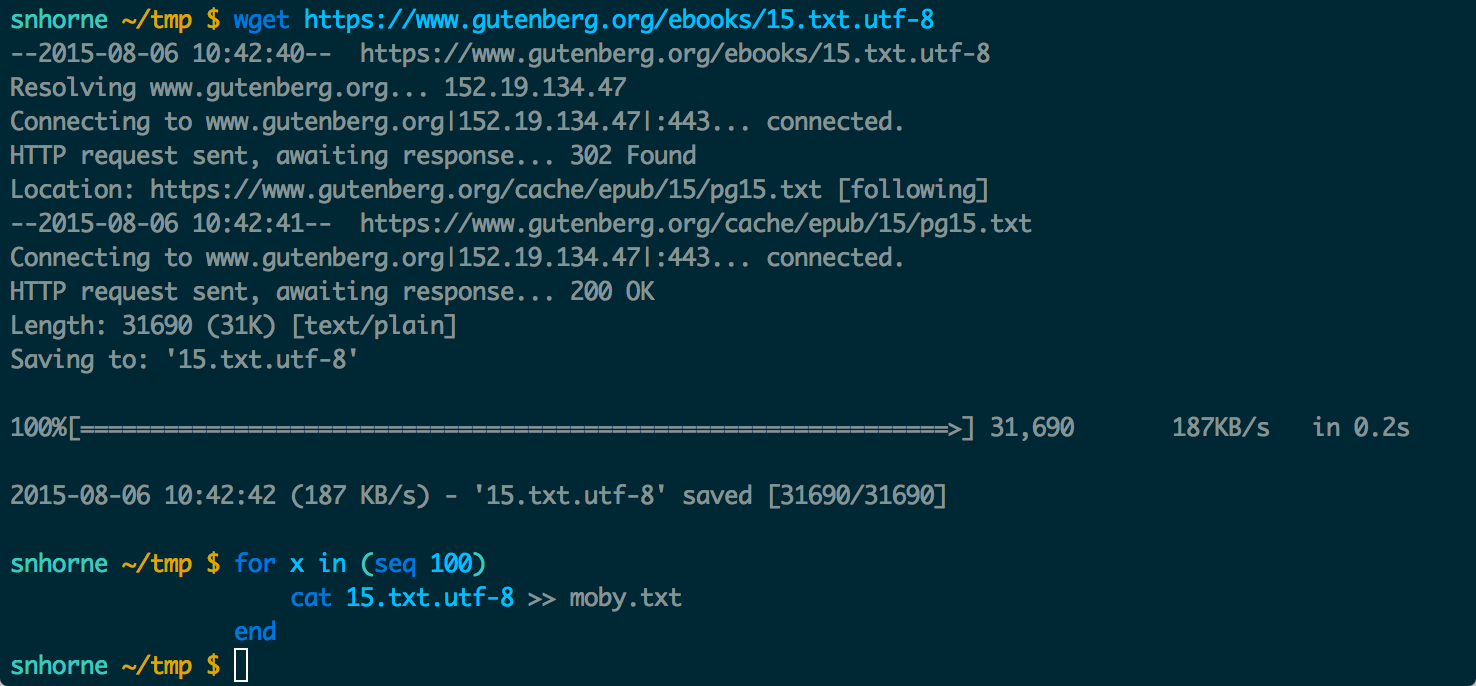 I downloaded moby dick and duplicated it several thousand times to get a large file to play with. The syntax isn't bash. It's fish shell. I think I'm the only one left who uses it.
I downloaded moby dick and duplicated it several thousand times to get a large file to play with. The syntax isn't bash. It's fish shell. I think I'm the only one left who uses it.How to get enumerators for a file
Here's a cool Ruby trick that you've probably used, even if you didn't know you were using it. Almost any method in Ruby that iterates over a collection will return an Enumerator object to you if you call it without passing in a block. What does that mean?
Consider this example. I can open a file, and use each line to print out each line. But if I call it without a block, I get an enumerator. The methods of interest are each_line, each_char and each_codepoint.
File.open("moby.txt") do |f|
# Print out each line in the file
f.each_line do |l|
puts l
end
# Also prints out each line in the file. But it does it
# by calling `each` on the Enumerator returned by `each_line`
f.each_line.each do |l|
puts l
end
end
These two examples look almost identical, but the second one holds the key to unlocking AMAZING POWERS.
Using a file's enumerator
Once you have an enumerator that "contains" all of the lines in a file, you can slice and dice those lines just like you can with any ruby array. Here are just a few examples.
file.each_line.each_with_index.map { |line, i| "Line #{ i }: #{ line }" }[3, 10]
file.each_line.select { |line| line.size == 9 }.first(10)
file.each_line.reject { |line| line.match /whale/i }
This is really cool, but these examples all have one big problem. They all load the entire file into memory before iterating over it. For a file containing 6,000 copies of Moby Dick, the lag is noticeable.
Lazy-loading the lines of the file
If we're scanning a large text file for the first 10 instances of the word "whale" then there's really no need to keep looking after the 10th occurrence. Fortunately it's dead easy to tell Ruby's enumerators to do this. You just use the "lazy" keyword.
In the examples below, we take advantage of lazy loading to do some pretty sophisticated things.
File.open("moby.txt") do |f|
# Get the first 3 lines with the word "whale"
f.each_line.lazy.select { |line| line.match(/whale/i) }.first(3)
# Go back to the beginning of the file.
f.rewind
# Prepend the line number to the first three lines
f.each_line.lazy.each_with_index.map do |line, i|
"LINE #{ i }: #{ line }"
end.first(3)
f.rewind
# Get the first three lines containing "whale" along with their line numbers
f.each_line.lazy.each_with_index.map { |line, i| "LINE #{ i }: #{ line }" }.select { |line| line.match(/whale/i) }.first(3)
end
It's not just for files
Sockets, pipes, serial ports - they're represented in Ruby using the IO class. That means that they all have each_line, each_char and each_codepoint methods. So you can use this trick for all of them. Pretty neat!
It's not magic
Unfortunately, lazy enumerators only speed things up if task you're trying to accomplish doesn't require that the entire file be read. If you're searching for a word that only occurs on the last page of the book, you have to read the whole book to find it. But in that case this approach shouldn't be any slower than a non-enumerator approach.


 Molly Struve, Sr. Site Reliability Engineer, Netflix
Molly Struve, Sr. Site Reliability Engineer, Netflix
